
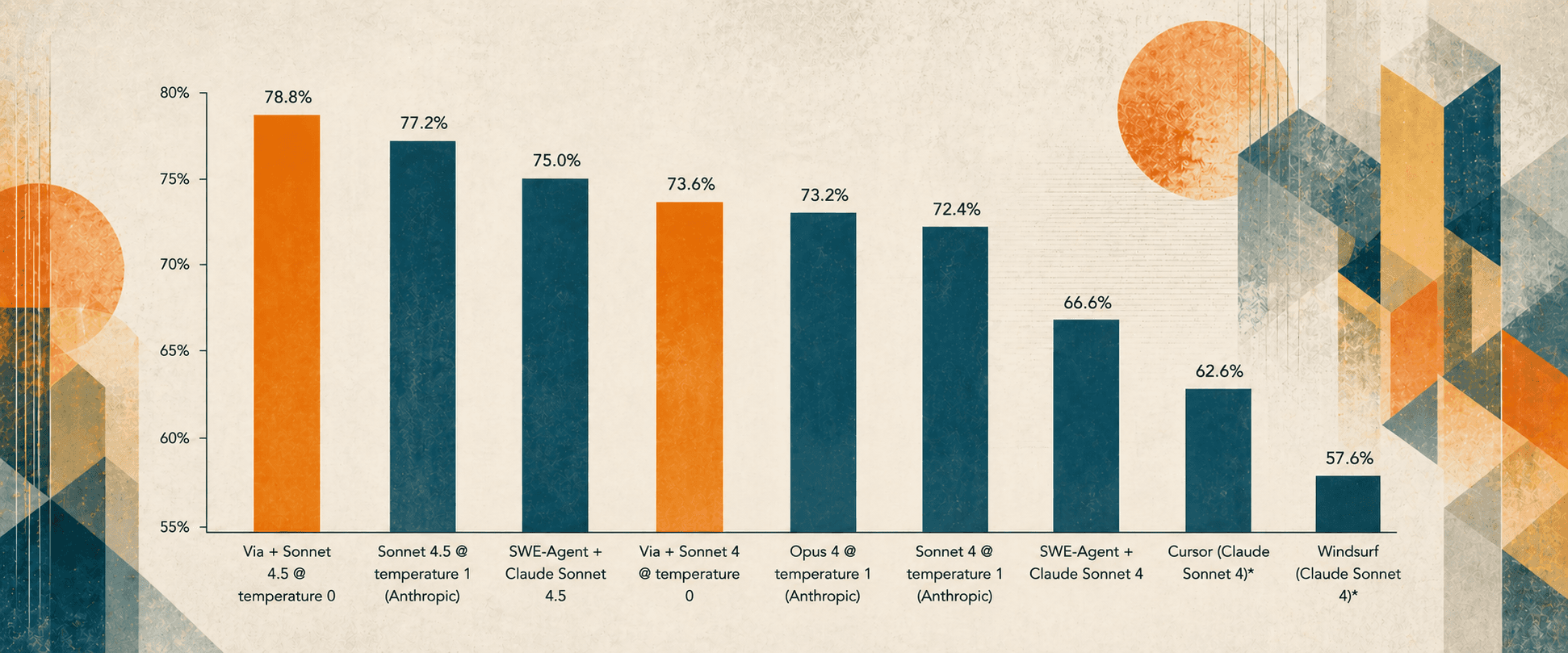
In March 2025, coding models were far from their current capabilities. AI was a copilot, not on autopilot. Anthropic's Claude Sonnet 3.7 model had just surpassed 62% on SWE-Bench Verified, the most ubiquitous benchmark for agentic coding. Claude Code was yet to be released.
Coding accuracy was one of AI's most important research problems. It became the basis for Via's initial hypothesis: applying classical, deterministic techniques from information and graph theory to non-deterministic LLMs could improve the accuracy of generated code.
As is now well-known, context is a critical factor in ensuring LLMs provide users accurate output. For AI coding tasks, the quality of the code context provided to the LLM is closely tied to the accuracy of the code to be generated. Prior to Via, the state of the art addressed context retrieval with semantic search, matching code based on syntactic similarity rather than exact relationships. This approach is inherently approximate, often failing to reliably capture deeper structural dependencies across a codebase.
Through our algorithms, Via held the #1 rank on SWE-Bench Verified, the primary benchmark for assessing agentic coding, from June to December of 2025. Via's algorithms outperformed Anthropic, OpenAI, and Google on their own LLMs, even as new generations of models were released. Via produced the most accurate code in the world.